千万量级的数据,用 MySQL 要怎么存?
初学者在看到这个问题的时候,可能首先想到的是 MySQL 一张表到底能存放多少条数据?
根据 MySQL 官方文档的介绍,MySQL 理论上限是 (232)2 条数据,然而实际操作中,往往还受限于下面两条因素:
- myisam_data_pointer_size,MySQL 的 myisam_data_pointer_size 一般默认是 6,即 48 位,那么对应的行数就是 248-1。
- 表的存储大小 256TB
那有人会说,只要我的数据大小不超过上限,数据行数也不超过上限,是不是就没有问题了?其实不尽然。
在实际项目中,一般没有哪个项目真的触发到 MySQL 数据的上限了,因为当数据量变大了之后,查询速度会慢的吓人,而一般这个时候,你的数据量离 MySQL 的理论上限还远着呢!
传统的企业应用一般数据量都不大,数据也都比较容易处理,但是在互联网项目中,上千万、上亿的数据量并不鲜见。在这种时候,还要保证数据库的操作效率,我们就不得不考虑数据库的分库分表了。
那么接下来就和大家简单聊一聊数据库分库分表的问题。
# 数据库切分
看这个名字就知道,就是把一个数据库切分成 N 多个数据库,然后存放在不同的数据库实例上面,这样做有两个好处:
- 降低单台数据库实例的负载
- 可以方便的实现对数据库的扩容
一般来说,数据库的切分有两种不同的切分规则:
- 水平切分
- 垂直切分
接下来我们就对这两种不同的切分规则分别进行介绍。
# 水平切分
先来一张简单的示意图,大家感受一下什么是水平切分:
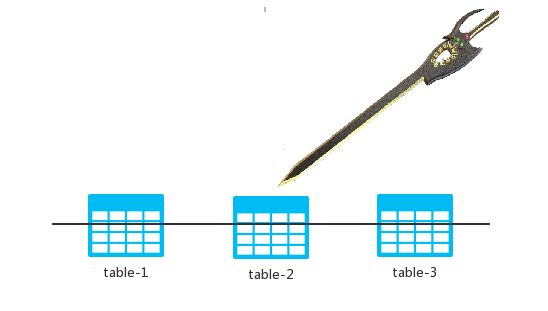
假设我的 DB 中有 table-1、table-2 以及 table-3 三张表,水平切分就是拿着我的绝世好剑,对准黑色的线条,砍一剑或者砍 N 剑!
砍完之后,将砍掉的部分放到另外一个数据库实例中,变成下面这样:
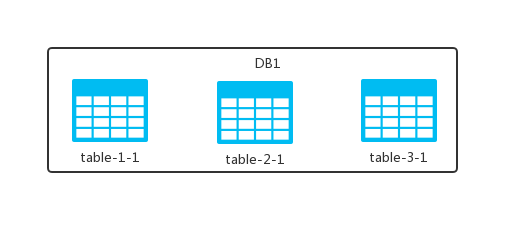
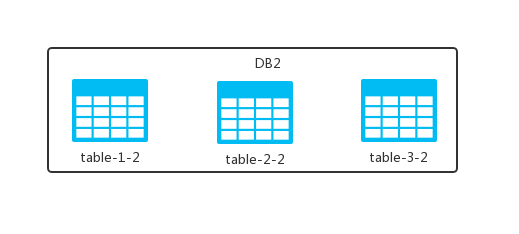
这样,原本放在一个 DB 中的 table 现在放在两个 DB 中了,观察之后我们发现:
- 两个 DB 中表的个数都是完整的,就是原来 DB 中有几张表,现在还是几张。
- 每张表中的数据是不完整的,数据被拆分到了不同的 DB 中去了。
这就是数据库的水平切分,也可以理解为按照数据行进行切分,即按照表中某个字段的某种规则来将表数据分散到多个库之中,每个表中包含一部分数据。
这里的某种规则都包含哪些规则呢?这就涉及到数据库的分片规则问题了,这个松哥在后面的文章中也会和大家一一展开详述。这里先简单说几个常见的分片规则:
- 按照日期划分:不容日期的数据存放到不同的数据库中。
- 对 ID 取模:对表中的 ID 字段进行取模运算,根据取模结果将数据保存到不同的实例中。
- 使用一致性哈希算法进行切分。
详细的用法,将在后面的文章中和大家仔细说。
# 垂直切分
先来一张简单的示意图,大家感受一下垂直切分:
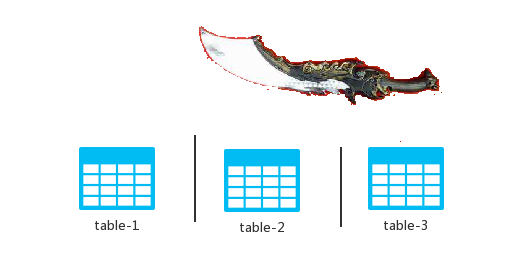
所谓的垂直切分就是拿着我的屠龙刀,对准了黑色的线条砍。砍完之后,将不同的表放到不同的数据库实例中去,变成下面这个样子:


这个时候我们发现如下几个特点:
- 每一个数据库实例中的表的数量都是不完整的。
- 每一个数据库实例中表的数据是完整的。
这就是垂直切分。一般来说,垂直切分我们可以按照业务来划分,不同业务的表放到不同的数据库实例中。
老实说,在实际项目中,数据库垂直切分并不是一件容易的事,因为表之间往往存在着复杂的跨库 JOIN 问题,那么这个时候如何取舍,就要考验架构师的水平了!
# 优缺点分析
通过上面的介绍,相信大家对于水平切分和垂直切分已经有所了解,优缺点其实也很明显了,松哥再来和大家总结一下。
# 水平切分
- 优点
- 水平切分最大的优势在于数据库的扩展性好,提前选好切分规则,数据库后期可以非常方便的进行扩容。
- 有效提高了数据库稳定性和系统的负载能力。拆分规则抽象好, join 操作基本可以数据库做。
- 缺点
- 水平切分后,分片事务一致性不容易解决。
- 拆分规则不易抽象,对架构师水平要求很高。
- 跨库 join 性能较差。
# 垂直切分
- 优点
- 一般按照业务拆分,拆分后业务清晰,可以结合微服务一起食用。
- 系统之间整合或扩展相对要容易很多。
- 数据维护相对简单。
- 缺点
- 最大的问题在于存在单库性能瓶颈,数据表扩展不易。
- 跨库 join 不易。
- 事务处理复杂。
# 结语
虽然 MySQL 中数据存储的理论上限比较高,但是在实际开发中我们不会等到数据存不下的时候才去考虑分库分表问题,因为在那之前,你就会明显的感觉到数据库的各项性能在下降,就要开始考虑分库分表了。
好了,今天主要是向大家介绍一点概念性的东西,算是我们分布式数据库中间件正式出场前的一点铺垫。
参考资料:
- MySQL 官方文档